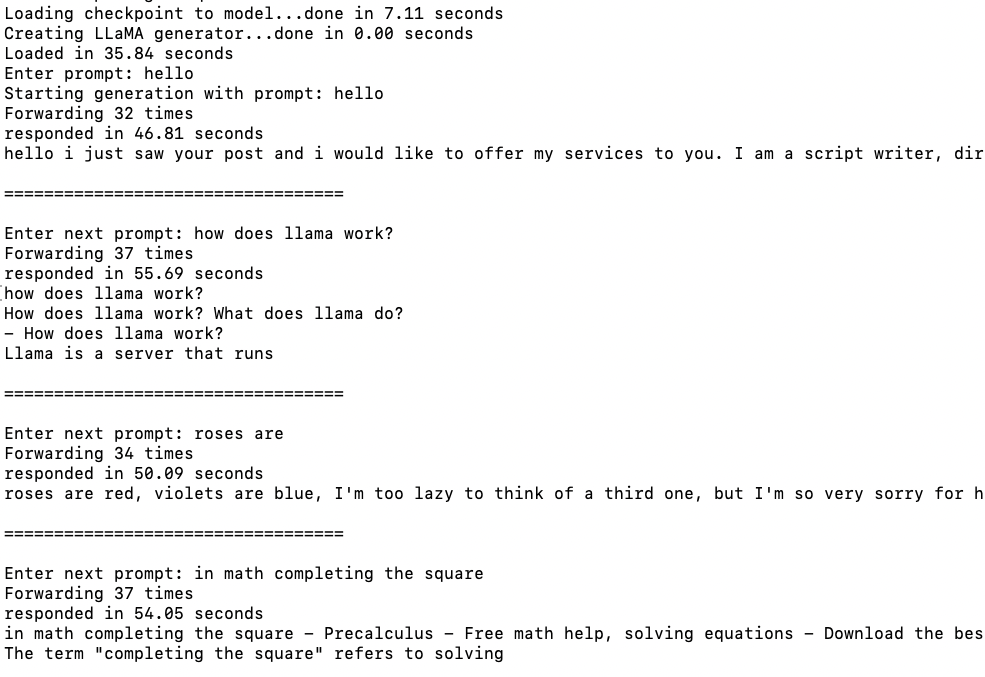
Stanford Alpaca takes the LLaMA pre-trained model released by the Meta AI and “fine-tunes” the model to respond better to natural language questions and prompts (exactly what chatGPT does). Note, the screenshot above is from LLaMA, not from Alpaca. This shows you the value that alpaca adds as the output from the example LLaMA is pretty bad.
The trick to getting Alpaca installed, though, is getting all the pieces.
- Acquired llama from Meta … check
- Use huggingface/transformers to convert the llama weights to the appropriate form expected by alpaca … problems, many…
- pip install git+https://github.com/huggingface/transformers
- then clone the repo anyway … probably combine these to install from local repo after cloning, but oh well…
git clone “https://github.com/huggingface/transformers” - 7:27am … yay running … python src/transformers/models/llama/convert_llama_weights_to_hf.py –input_dir /Users/briantoone/homegpt/weights –model_size 7B –output_dir /Users/briantoone/homegpt/weights
- low_mem_usage requires accelerate…
pip install accelerate - 7:30am … restarted conversion … missing tokenizer.model … didn’t download correctly … downloaded again
- 7:44am finished with no errors! output file listing:
check!!!
- git clone “https://github.com/tatsu-lab/stanford_alpaca”
- uh-oh … dead-end (maybe just a cul-de-sac) …
nccl not built into pytorch … stanford_alpaca expects NVIDIA drivers and cuda enabled:
https://github.com/facebookresearch/llama/issues/50#issuecomment-1454151503
- uh-oh … dead-end (maybe just a cul-de-sac) …
- attempting the cpu-only fork of llama (instead of alpaca)
- git clone “https://github.com/b0kch01/llama-cpu”
- pip install -r requirements.txt
- pip install -e .
- export PYTORCH_ENABLE_MPS_FALLBACK=1
export PYTORCH_MPS_HIGH_WATERMARK_RATIO=0.0 - success!
Overall – partial success … alpaca optimized for nvidia/cuda, not compatible with new m1 macs integrated gpu’s (MPS-optimized)

But there’s hope! I have another office computer that has a nice GeForce GT 1030 graphics card. Unfortunately, it’s not currently setup with python at all.
This is great opportunity, though, to see how to configure Windows 11 to run pytorch. Will report back with a separate blog about that soon!