3/21 6:48AM. The genie truly is out of the bottle. I am in the process of installing LLaMA on my home mac studio. Here’s the play-by-play.
LLaMA is based on PyTorch, so in this part, I install and activate the latest version of pytorch optimized for my M1 Ultra.
Some notes … pyenv vs virtualenv … apparently the miniforge m1 setup I did for tensorflow uses pyenv instead of virtualenv. But I used virtualenv to create a new environment for pythorch
cd ~/.pyenv/versions
virtualenv envs/pytorchenvThis created a new environment folder for miniconda3 sitting alongside miniforge-3.4.10.3-10. I edited the “version” file to look like this:
#miniforge3-4.10.3-10
miniconda3Then I activated it as follows:
pyenv activateI didn’t specify which environment because I figured the “version” file took care of that. Everything worked (I think).

Then to install pytorch:
conda install pytorch torchvision -c pytorchSuccess!
Running this tiny program was NOT fast. Presumably a lot has to be loaded for the torch framework. Let’s try it on something more meaningful, like a neural network. How about one for classifying the fashion MNIST with 80% accuracy, with two hidden layers having 512 neurons each and one output layer, all using RELU activation function.
I ran the program twice: once specifying the mps_device (i.e., the 48 core integrated M1 ultra graphics processor) and again using cpu_device. For both tests, I trained on all 60,000 training images for 30 epochs and tested on 10,000 test images. Here were the results:
| Training | Testing | Accuracy | |
| mps_device (GPU) | 104s | 0.61s | 80.9% |
| cpu_device (CPU) | 93s | 0.29s | 81.2% |
Results were surprising as it was faster using the CPU than using the GPU. But let’s try again with a deeper convolutional neural net.
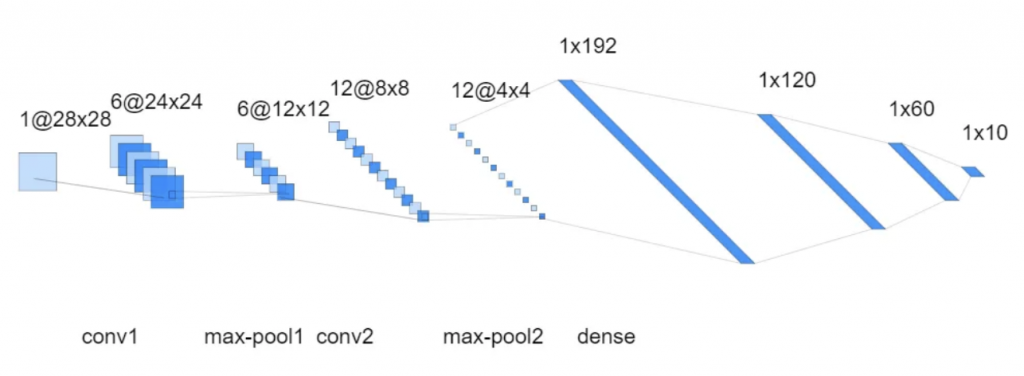
Now, we are getting somewhere, i.e., this is the kind of speed-up I was hoping for when I purchased a $5k mac studio.
| Training | Testing | Accuracy | |
| mpu_device (GPU) | 229s | 0.71s | 88.3% |
| cpu_device (CPU) | 664s | 0.60s | 87.6% |
3/21 10:05AM Apple M1 configuration and testing of PyTorch complete! There was a lot of reading and coding to adapt the example neural networks I found to the Apple M1 optimized code.
So what’s going on with the results? Why is the CPU sometimes faster than the GPU? Overhead, economies of scale, etc… these are the general reasons. Specifically, a deeper neural network has to perform orders of magnitude more calculations than a smaller linear network. The number of computations that can benefit from the parallelization available in the 48 core GPU vastly exceeds the overhead required to represent and transform the data into a suitable format for the GPU. In a simpler neural network, the overhead ends up outweighing the performance speed-up, whereas on a deeper Convolutional Neural Network (CNN) the computational speed-up outweighs the overhead.
Note that the testing is still faster for the CPU because the overhead of preparing the test data to run on the GPU outweighs the computational speed-up. Apple makes note of this on one of their machine learning pages…
When training ML models, developers benefit from accelerated training on GPUs with PyTorch and TensorFlow by leveraging the Metal Performance Shaders (MPS) back end. For deployment of trained models on Apple devices, they use coremltools, Apple’s open-source unified conversion tool, to convert their favorite PyTorch and TensorFlow models to the Core ML model package format. Core ML then seamlessly blends CPU, GPU, and ANE (if available) to create the most effective hybrid execution plan exploiting all available engines on a given device. It lets a wide range of implementations of the same model architecture benefit from the ANE even if the entire execution cannot take place there due to idiosyncrasies of different implementations. This workflow is designed to make it easy for developers to deploy models on Apple devices without having to worry about the capabilities of any particular device or implementation.
https://machinelearning.apple.com/research/neural-engine-transformers
Heading out now to teach my Artificial Intelligence class, but I will continue this in a separate Part 2 post after class!