Having recently upgraded to a new server for many of my research websites, I have blogged about MySQL 8.0 spatial indexing and migrating from earlier versions. During many hours of trying to get everything to work, I discovered that much of my GPS data is bloated with linestrings full of duplicate adjacent points.
The primary reason for this bloat is that I wasn’t pre-processing any of the data as it was imported from my Garmin GPS devices. If you are recording data and not moving but leave the timer running then the GPS will record the same exact latitude/longitude every second. Even for a one-minute stop, this leads to 60 duplicate points recorded. Multiply this by many stops in a ride and thousands and thousands of rides, and it leads to a lot of pointless redundant data being stored in my LINESTRING objects.
Even for my own personal usage, I have enough data that this really slows things down when loading a lifetime’s worth of rides for analysis and map creation. Imagine the impact of scaling to many users. For this reason, I’m about to tackle the following: 1) add a pre-processing script to remove duplicates during import and 2) remove all the duplicates from existing data already imported into the database.
Pre-processing during import
This is a little bit tricky for a few reasons. First, Garmin stores its latitude/longitude coordinates as “semicircles”, which requires a strange conversion to normal lat/lng decimal degree coordinates. Second, I have to extract this information from a binary FIT file, for which there was no PHP library for processing at the time that I initially created topocreator.
There was, however, a Java FIT library. So I created a Java program that gets launched from my php script to process the FIT file and return all the data into a space separate list of “records” for easy processing from within php. This is the “$parts” variable referenced in the screenshot below, which shows how I am checking to make sure that the lat/lng have actually changed before importing.
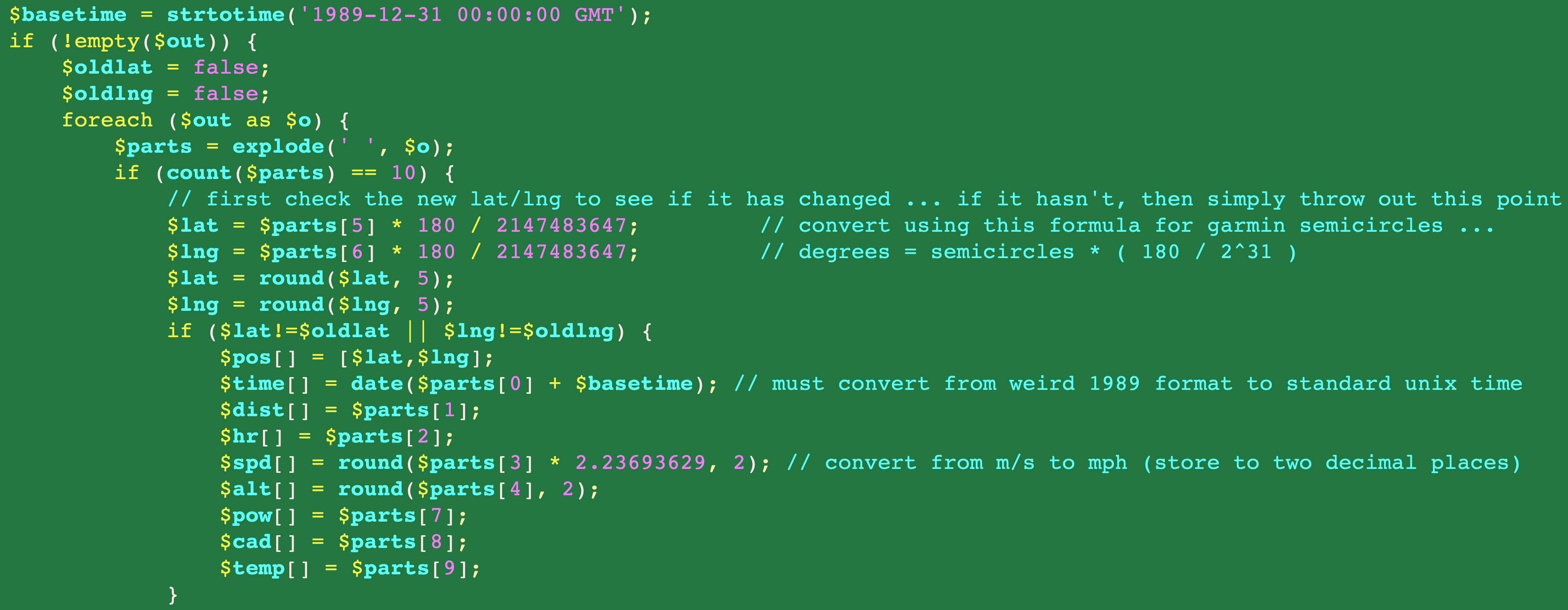
Removing existing duplicates
This is a bit more challenging because the current number of GPS points (even the duplicate ones) exactly matches the number of heart rate, speed, cadence, time, temperature, etc… points imported. My pre-processing will simply eliminate the import of the extra data as well (which pretty much doesn’t matter if you are never moving from the same spot, although some edge cases when GPS is turned off (e.g., stationary bike rides) will not have any data at all). What I have to keep reminding myself is that the primary purpose of this website is for MAPS and ROUTES … neither of which applies for stationary bike rides.
The million dollar question is whether any of my code anywhere is expecting those counts to be the same. I’m pretty sure the answer to that question is no, but is it worth the effort to dig through all the code and make sure … and what happens if I remove all the duplicates (creating the count discrepancy) and find out later that it mattered.
To answer the first question, I’m confident enough that I’m not relying on equal “point counts” that it is not worth the time and effort to verify.
For the second question, if I find out I’m wrong later, I have many, many backups of the original GPS files so that in the worst case scenario, I can simply re-import everything.
This leads us to the primary topic that inspired this post – how to remove duplicate adjacent points from a LINESTRING in MySQL 8.0. Postgres has much more extensive support for spatial datatypes including many more functions that mysql is only finally starting to add. Postgres has a ST_RemoveRepeatedPoints function that would do exactly what I need it to do. The closest MySQL 8.0 spatial function currently implemented is the ST_Simplify(g, max_distance), which seeks to store fewer points on straight line segments as well as (presumably) removing duplicate points.
Unfortunately, when setting max_distance to 0, you get an error. So instead, since I have been forced to keep my SRID as cartesian (0), I have to specify this distance in coordinates. Google maps considers 0.00001 away to be a “different” point in most of its documentation, so I’m going to go one order of magnitude further and require it to be 0.000001 away. Hopefully this will remove all the duplicate points. The chart below shows the results of experimenting with the max_distance variable.
| max_distance | Length new (diff) | Number of points new (diff) |
| original | 1.2725 | 9035 |
| 0.001 | 1.23217 (-0.04033) | 143 (-8892) |
| 0.0001 | 1.26566 (-0.00634) | 496 (-8539) |
| 0.00001 | 1.27127 (-0.00123) | 2246 (-6789) |
| 0.000001 | 1.2725 (-0.00000) | 7052 (-1983) |
As you can see from the last row, removing 1,983 points from the linestring made no change in the overall distance of the linestring. I’m sure a lot of these were duplicate points, but also some straight line points that can be avoided as well.
The query that generated the results above for all routes in the database is shown below:
SELECT t.item_id,
round(st_length(t.pts), 5) AS distorig,
st_numpoints(t.pts) AS numptsorig,
round(st_length(t.pts3), 5) AS dist3,
st_numpoints(t.pts3) AS numpts3,
round(st_length(t.pts4), 5) AS dist4,
st_numpoints(t.pts4) AS numpts4,
round(st_length(t.pts5), 5) AS dist5,
st_numpoints(t.pts5) AS numpts5,
round(st_length(t.pts6), 5) AS dist6,
st_numpoints(t.pts6) AS numpts6,
st_length(t.pts6)-st_length(t.pts) AS diff6
FROM
(SELECT item_id,
pts,
st_simplify(pts, 0.001) AS pts3,
st_simplify(pts, 0.0001) AS pts4,
st_simplify(pts, 0.00001) AS pts5,
st_simplify(pts, 0.000001) AS pts6
FROM route_segments
WHERE item_id in
(SELECT item_id
FROM route_segments
GROUP BY item_id
HAVING count(id)=1) ) t
ORDER BY diff6;
And just to make absolutely sure that I wasn’t going to lose any of the route data as well as to demonstrate differences in the functionality of ST_Simplify, I’ve displayed the same route in a variety of colors overlaid on top of each other based on the simplification (original = yellow, 0.001 = red, 0.0001 = orange, 0.00001 = green, 0.000001 = blue). Note that the green and blue are indistinguishable in many places from the original route … so much so that the original “yellow” isn’t visible anywhere in the screenshot below (even zoomed in!)
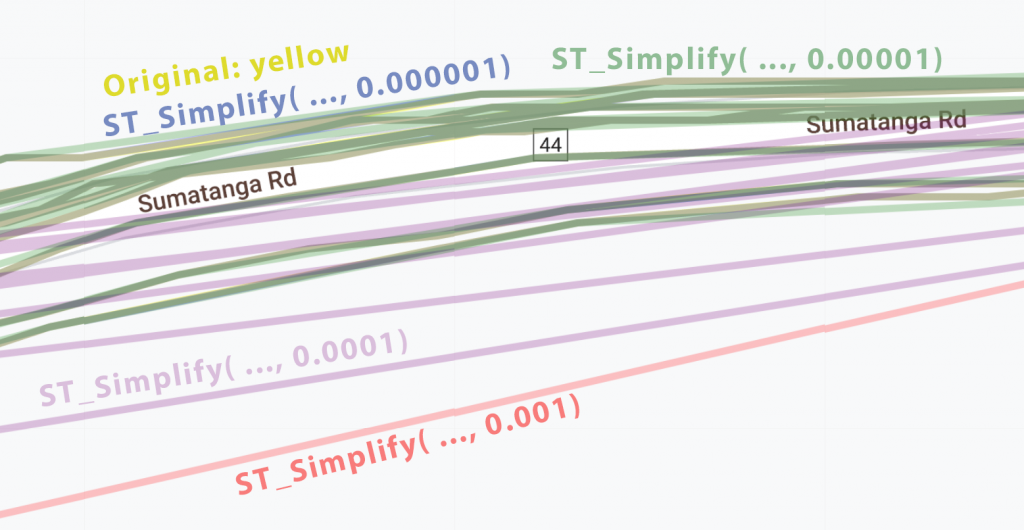
I’m convinced based on these results that the following query should greatly simplify the database without losing any significant GPS data that affects the actual path recorded.
UPDATE route_segments SET pts = ST_Simplify(pts, 0.000001);
To see how much “bloat” was removed, I measured the size of the route_segments table before and after executing the command above.
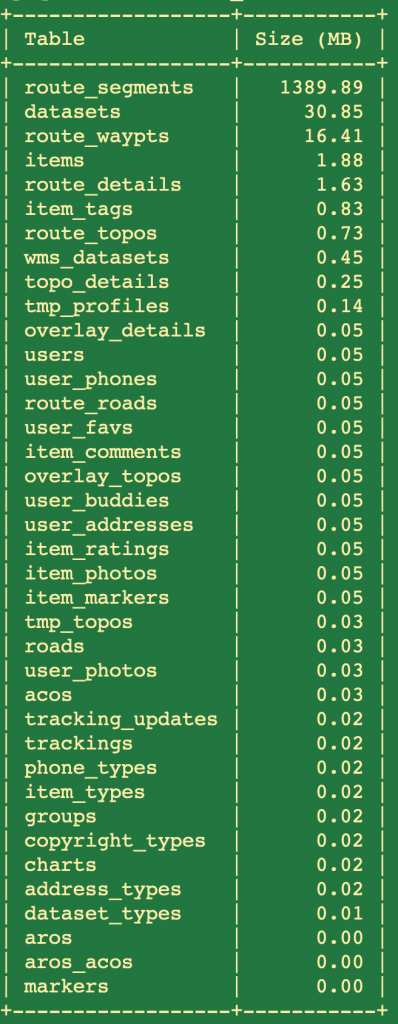
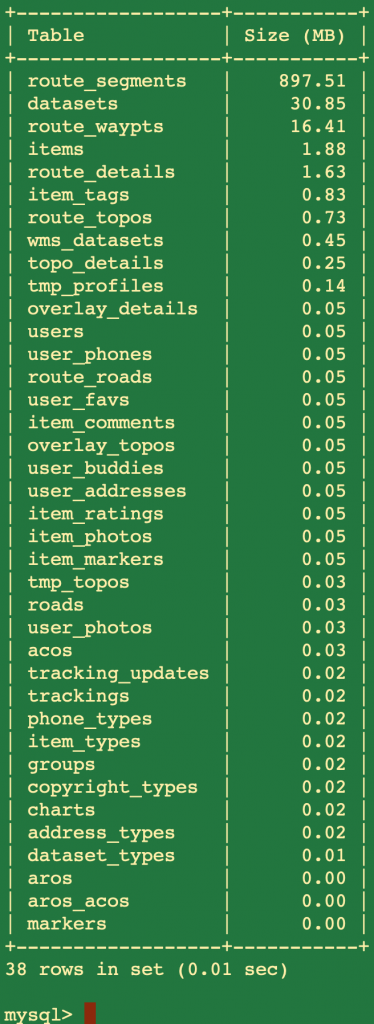
The storage savings isn’t that important now that I essentially have unlimited storage running everything locally, but my algorithms for processing the route data should be significantly faster since there are far fewer points to process!
Furthermore, now that I know about ST_Simplify, I can remove my handcrafted slicing/dicing code to remove points to display a polyline with fewer points. I can rely on ST_Simplify to do this much more quickly. And the final result…
